The evaluation of RecSys - Part 1
Recommendation systems (RecSys) play a critical role in modern AI-driven applications. From e-commerce to social media, search engines, and online advertising, personalized recommendations significantly impact user experience and business revenue. This blog series is intended for both beginners and experienced ML practitioners who want to understand the evaluation of recommendation systems in a structured manner.
I’ll discuss early tech briefly and deep dive into the latest innovations. For each technique, I’ll break down key concepts, their loss functions (how they learn), inputs/outputs, features, and limitations—why they weren’t enough, and how the next breakthrough fixed the flaws. But first things first:
1. What is a Recommendation System?
A Recommendation System (RecSys) is an AI-driven system designed to predict and suggest relevant items (products, content, services) to users based on their past interactions, preferences, and contextual signals.
Why is it important?
It reduces information overload and boosts user engagement by personalizing content delivery, making your online experience smoother while helping companies rake in revenue.
Use Cases
| Domain | Examples | Application |
|---|---|---|
| E-commerce | Amazon, eBay, Alibaba | Product recommendations |
| Streaming | Netflix, YouTube, Spotify | Content recommendations |
| Social Media | FB, Insta, TikTok, Twitter | Feed ranking, friends/pages suggestion |
| Search Engines | Google, Bing, Baidu | Personalized search results |
| Online Advertising | Google Ads, Meta Ads, TikTok Ads | Personalized ad ranking |
| Healthcare | Clinical Decision Support | Personalized treatment recommendations |
| Finance | Stock Market, PayPal, Banking | Personalized financial insights, fraud detection |
| Geolocation | Uber, Doordash, Airbnb | Personalized ride, restaurant, rental suggestions |
2. Evaluation Overview: From Legacy to State-of-the-Art
2000–2010: Classical Techniques
- Heuristic Methods: Rule-based (e.g., Amazon’s “Customers who bought this also bought”).
- Collaborative Filtering (CF): User & item-based CF using similarity metrics (cosine, Pearson).
- Content-based Filtering: TF-IDF, cosine similarity, word embeddings.
- Matrix Factorization (MF): SVD, ALS, NMF for latent factor modeling (Netflix Prize 2006).
2010–2015: ML-Based
- Factorization Machines (FM): Generalization of MF (used in CTR prediction).
- Gradient Boosted Trees (GBDT): XGBoost, LightGBM for ranking models (widely used in ads & search).
- Hybrid Models: CF + ML
2015–2020: Deep Learning-Based RecSys
- DeepFM: FM + DNN for learning feature interactions.
- Neural Collaborative Filtering (NCF): Replacing MF with deep networks.
- Multi-task Learning (MTL): Multi-objective optimization for RecSys (e.g., ads ranking).
- Graph Neural Networks (GNNs): PinSage (Pinterest), GAT-based RecSys.
- Sequential RecSys (RNN, Transformer): GRU4Rec, BERT4Rec, SecRec for session-based recommendations.
2020–Present: Gen AI-Powered RecSys
- LLMs for RecSys: ChatGPT, GPT-4, PaLM, Gemini for conversational RecSys.
- Retrieval-Augmented Generation (RAG): Using search + generation for recommendations.
- Diffusion Models: Generating recommendations using probabilistic diffusion.
- Multimodal RecSys: Combining text, image, video, and audio (e.g., TikTok).
- Reinforcement Learning (RL) in RecSys: Deep Q-Networks (DQN), PPO, Bandits (news feed ranking).
3. In Layman Terms (For non ML background)
Imagine you’re at a buffet with endless dishes, but you only have time to pick a few. A recommendation system is like a smart friend who knows your taste. There are three classic ways it works:
Content-Based Filtering (The “What You Like” Friend):
This friend looks at what you’ve eaten before—like spicy tacos—and suggests more spicy stuff, like chili soup. It builds a “you” profile (loves spicy!) and a “food” profile (this dish is spicy!) to match them up.
Example: You watch a sci-fi movie on Netflix, so it suggests Star Wars next because it’s similar. Easy, right?
Collaborative Filtering (The “Crowd Wisdom” Friend):
This friend doesn’t care what the food is—they watch other people. If you and your buddy both liked pizza, and your buddy also loved sushi, they’ll suggest sushi to you.
Example: On Amazon, you buy a phone case, and it suggests a charger because others who bought cases also grabbed chargers.
Matrix Factorization (The “Secret Code” Friend):
Now imagine your friend cracking a secret code. They don’t just look at what you ate or what others did—they figure out why you liked it.
Example: You rate action movies high on Netflix. It figures you like “fast pacing” and “hero vibes,” so it suggests Mad Max even if you’ve never seen it before.
Each method has strengths, but they stumble too—new users or items can confuse them, or they miss the bigger picture. That’s why we keep inventing better friends!
4. Technical Deep Dive
Content-Based Filtering
- Key Idea: Match users to items based on their features.
- How It Works: Build a profile for users (e.g., “likes sci-fi”) and items (e.g., “sci-fi movie”) using text features like TF-IDF or embeddings (word2vec). Compute similarity (cosine) between them.
- Input: User history (watched Star Trek), item metadata (movie tags).
- Output: Ranked list of similar items (Star Wars).
- Loss Function: Minimize ranking error (e.g., cosine distance) or maximize relevance (e.g., precision@k).
- Limitations: Only recommends items similar to past preferences, leading to filter bubbles. Cannot discover diverse recommendations (e.g., user likes Sci-Fi → never gets Comedy).
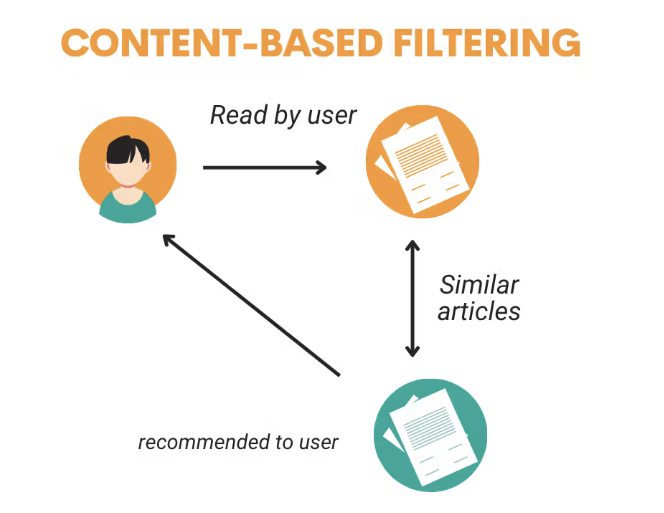
Fig 3: Content-based filtering [1]
Collaborative Filtering (CF)
- Key Idea: Use group behavior to predict individual tastes.
- It assumes that users with similar preferences will like similar items.
Neighborhood methods:
- User-Based: Find users like you (similar ratings), borrow their likes.
Math: Cosine similarity between user rating vectors. - Item-Based: Find items like what you rated (similar users liked them).
Math: Cosine similarity between item rating vectors.
Latent factor models:
Represent users and items in a lower-dimensional latent space, driven by hidden factors (e.g., genres, tastes). This leads to Matrix Factorization (MF).
- Input: User-item rating matrix (sparse!)
- Output: Top-N items you might rate high.
- Loss Function: Minimize prediction error (e.g., RMSE).
- Limitations: Cold start problem. Also, If a movie or product is not popular, it will never get recommended.
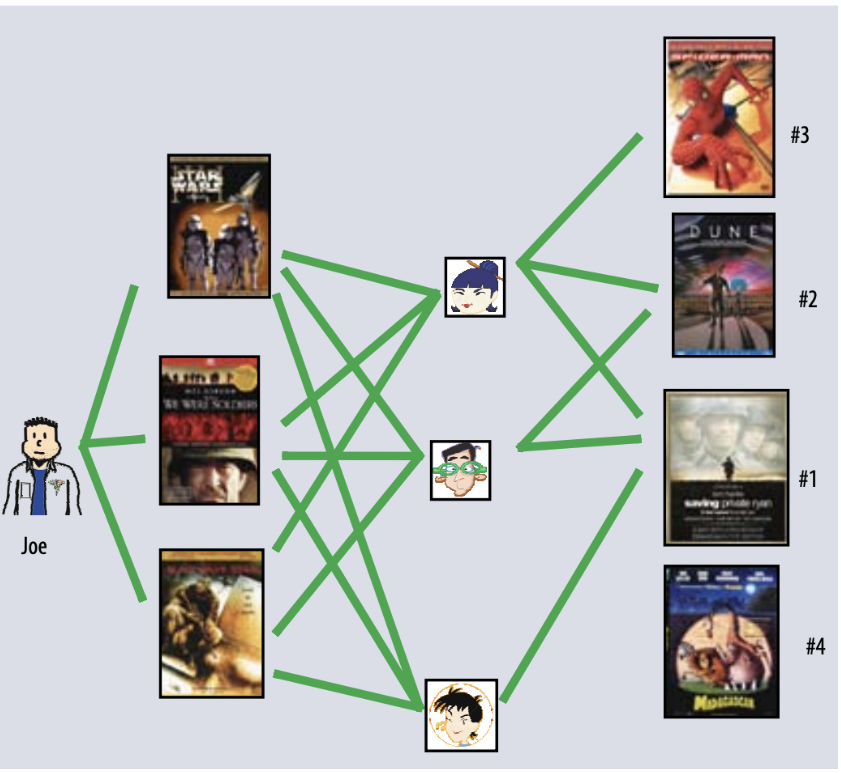
Fig 3: The user-oriented neighborhood method. [2]
Matrix Factorization (MF)
- Key Idea: Decode ratings into hidden “factors” (tastes) for users and items.
- How It Works: Picture a giant grid with users as rows and items as columns, ratings in cells. Most cells are blank (no ratings). MF fills in the blanks by estimating latent traits.
Math: Break the matrix into two:
- User factors \( p_u \)
- Item factors \( q_i \)
- Predicted rating \( \hat{r}_{ui} = p_u^T q_i \)
Loss Function:
$$ \text{Loss} = \sum (r_{ui} - q_i^T p_u)^2 + \lambda (||q_i||^2 + ||p_u||^2) $$
- Optimizer: SGD or ALS
- Limitations: Assumes linear interactions, works only for explicit feedback.
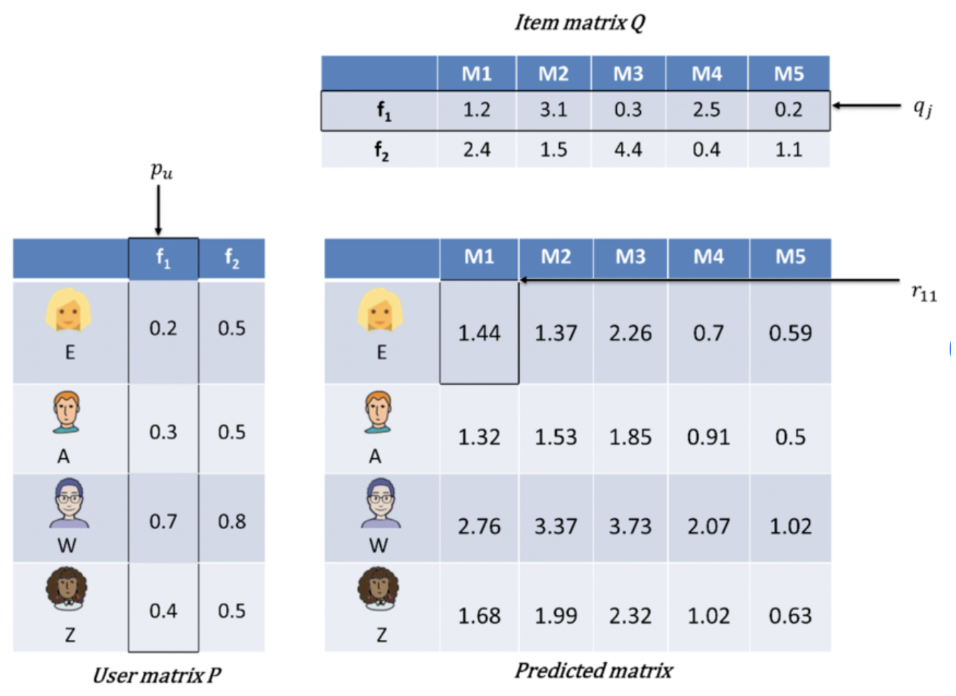
Fig 3: A simplified version of Matrix factorization [3]
Why Not Just SVD?
SVD is related to MF and captures latent structure, but:
- Sparsity: SVD requires a full matrix.
- Scalability: Expensive for large datasets.
- Overfitting: Without constraints, it fits noise.
Regularization:
Helps address sparsity and overfitting. Regularized MF works only on observed ratings and avoids costly imputation.
Conclusion
The progression from content-based filtering (Fig 1) to collaborative filtering (Fig 2), and finally to MF (Fig 3), reflects a shift toward leveraging latent structures in sparse data. Neighborhood methods provided an initial collaborative approach, but latent factor models, inspired by SVD, offered scalability and accuracy. SVD’s limitations spurred regularized MF, focusing on observed ratings, with SGD and ALS optimizing this process for real-world systems.
References
- StrataScratch
- Koren, Yehuda, et al. “Matrix Factorization Techniques for Recommender Systems.” Computer 42.8 (2009): 30–37.
